Understanding SOLID Principles in Software Development: Creating Maintainable and Scalable Code.
As a software developer, it is important to create code that is not only functional but also maintainable and scalable. The SOLID principles provide a set of guidelines that can help developers achieve these goals by promoting modularity, flexibility, and testability. In this discussion, we will explore each of the SOLID principles in detail and discuss their benefits in software development. By the end of this conversation, you will have a deeper understanding of how to apply these principles in your own code and how they can improve the quality and efficiency of your software development process.
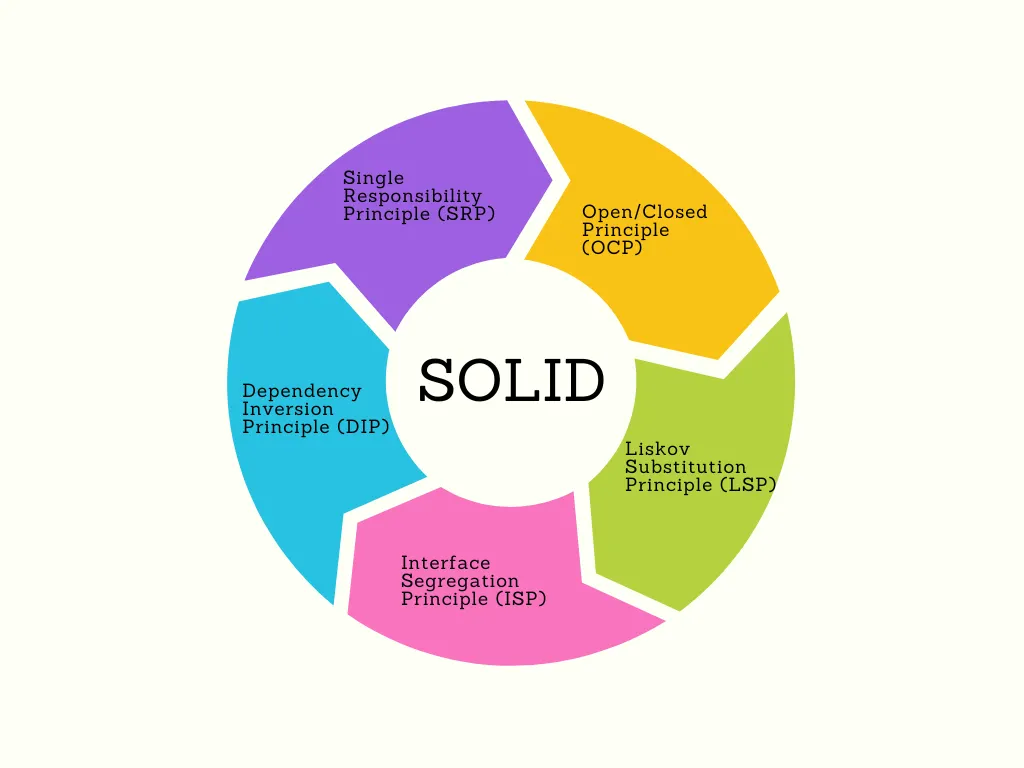
SOLID is an acronym for five design principles that can help developers to create more maintainable and scalable software systems. These principles were first introduced by Robert C. Martin (also known as Uncle Bob) and are widely used in software development. The SOLID principles are:
- Single Responsibility Principle (SRP)
- Open/Closed Principle (OCP)
- Liskov Substitution Principle (LSP)
- Interface Segregation Principle (ISP)
- Dependency Inversion Principle (DIP)
To better understand the SOLID principles, let’s examine each one in detail with a real-world example. For the purposes of this article, we will be using React.js to provide code samples. However, it’s important to note that these principles can be applied to various programming languages and paradigms.
- Single Responsibility Principle (SRP):
It suggests that a class should have only one reason to change or one responsibility, making the code more modular, flexible, maintainable, and easy to understand. When a class has too many responsibilities, it becomes difficult to modify and may introduce unwanted dependencies. By separating responsibilities into different classes, developers can make their code more maintainable and testable.
Let’s consider an example of a simple login form component that handles both user input validation and login authentication:
import React, { useState } from 'react';
function LoginForm() {
const [username, setUsername] = useState('');
const [password, setPassword] = useState('');
const [errorMessage, setErrorMessage] = useState('');
const handleUsernameChange = (event) => {
setUsername(event.target.value);
};
const handlePasswordChange = (event) => {
setPassword(event.target.value);
};
const handleSubmit = (event) => {
event.preventDefault();
if (!username || !password) {
setErrorMessage('Please enter a username and password');
return;
}
// Authenticate user with backend API
authenticateUser(username, password)
.then(() => {
// Redirect to dashboard
window.location.href = '/dashboard';
})
.catch(() => {
setErrorMessage('Invalid username or password');
});
};
return (
<form onSubmit={handleSubmit}>
<div>
<label htmlFor="username">Username:</label>
<input
type="text"
id="username"
value={username}
onChange={handleUsernameChange}
/>
</div>
<div>
<label htmlFor="password">Password:</label>
<input
type="password"
id="password"
value={password}
onChange={handlePasswordChange}
/>
</div>
{errorMessage && <div>{errorMessage}</div>}
<button type="submit">Login</button>
</form>
);
}
export default LoginForm;In this example, the LoginForm component handles both input validation and authentication, which violates the SRP. A better approach is to separate these responsibilities into two separate components.
First, let’s create a new LoginFormValidator component that handles input validation:
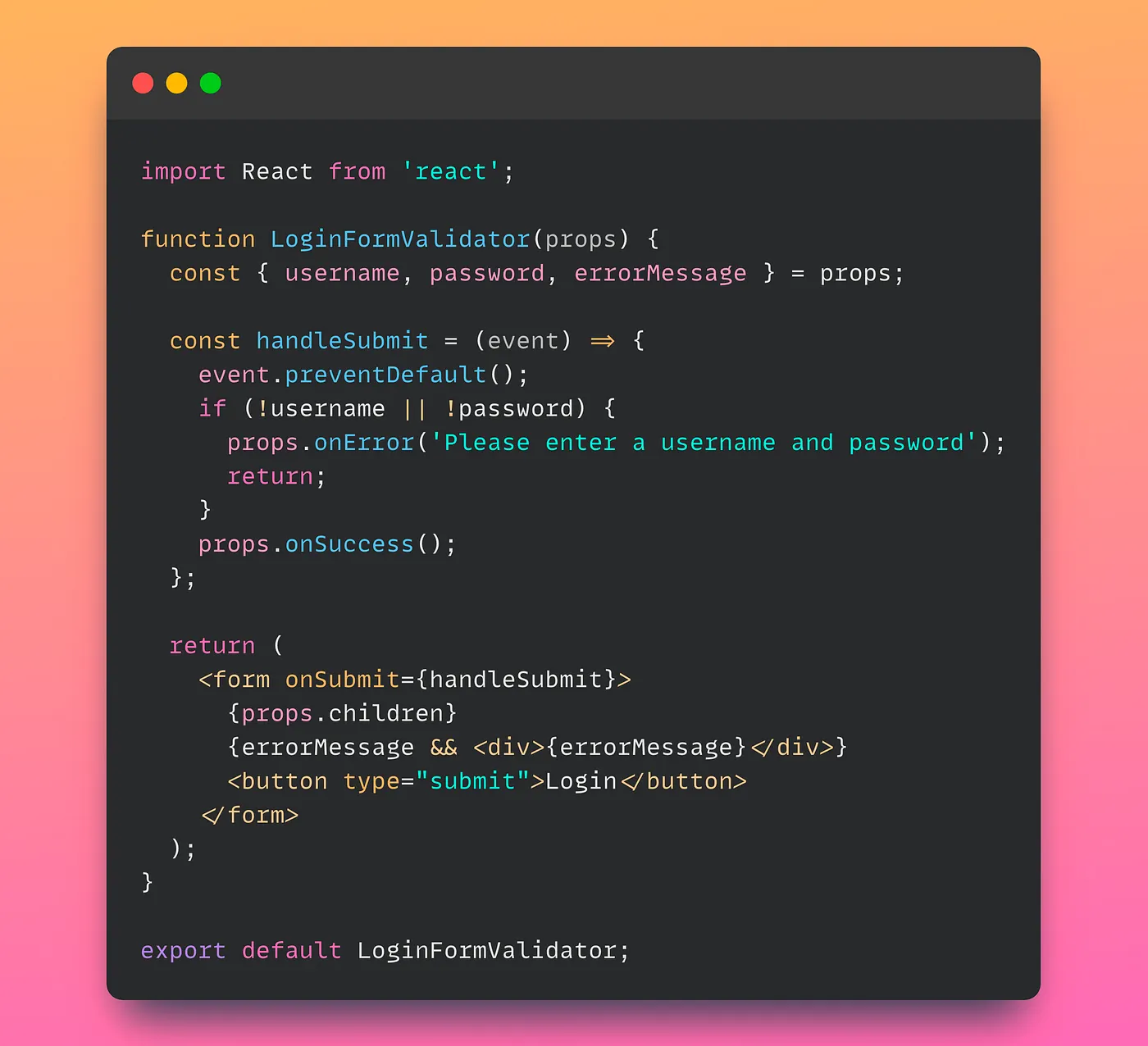
The LoginFormValidator component accepts the username, password, and errorMessage props from its parent component, and it handles input validation using a callback function that is passed as a prop. If the input is valid, the onSuccess callback is called; otherwise, the onError callback is called with an error message.
Next, let’s modify the original LoginForm component to use the LoginFormValidator component and handle authentication:
import React, { useState } from 'react';
import LoginFormValidator from './LoginFormValidator';
function LoginForm() {
const [username, setUsername] = useState('');
const [password, setPassword] = useState('');
const [errorMessage, setErrorMessage] = useState('');
const handleUsernameChange = (event) => {
setUsername(event.target.value);
};
const handlePasswordChange = (event) => {
setPassword(event.target.value);
};
const handleLoginSuccess = () => {
// Authenticate user with backend API
authenticateUser(username, password)
.then(() => {
// Redirect to dashboard
window.location.href = '/dashboard';
})
};
const handleLoginError = (error) => {
setErrorMessage(error);
};
return (
<LoginFormValidator
username={username}
password={password}
errorMessage={errorMessage}
onSuccess={handleLoginSuccess}
onError={handleLoginError}
>
<div>
<label htmlFor="username">Username:</label>
<input
type="text"
id="username"
value={username}
onChange={handleUsernameChange}
/>
</div>
<div>
<label htmlFor="password">Password:</label>
<input
type="password"
id="password"
value={password}
onChange={handlePasswordChange}
/>
</div>
</LoginFormValidator>
);
}
export default LoginForm;In this modified LoginForm component, the LoginFormValidator component handles input validation, and it calls the handleLoginSuccess callback if the input is valid. If there is an error, the handleLoginError callback is called with an error message, which is displayed in the UI.
By separating the responsibilities of input validation and authentication into two separate components, we have made the code more modular and easier to maintain. The LoginFormValidator component can be reused in other forms throughout the application, and the LoginForm component can focus solely on handling authentication logic. This is a good example of how the SRP can be applied in a React application to improve code quality and maintainability.
Applying the SRP not only makes code more maintainable, but it also makes it easier to test, as each class can be tested in isolation. Additionally, by adhering to the SRP, developers can more easily modify and extend the code, without having to worry about unintended side effects.
Overall, the SRP is an important principle for creating clean and maintainable code, and it helps to ensure that each class has a clear and focused purpose.
2. Open/Closed Principle (OCP):
It is a design principle in object-oriented programming that suggests that software entities should be open for extension but closed for modification. This means that a software component should be designed in such a way that it can be easily extended with new functionality without requiring changes to its existing code.
In the example code of a simple login form component that handles both user input validation and login authentication in a functional component, the OCP can be applied as follows:
- Separation of Concerns: The first step is to separate the user input validation and login authentication concerns into separate modules. This separation ensures that each module is responsible for a single task and can be extended independently without affecting the other module. For example, we can create two separate functions for input validation and login authentication.
- Abstraction: The second step is to abstract the implementation details of each module behind an interface. This interface should define a set of methods that the module must implement to fulfill its responsibilities. For example, we can define an interface for the validation module that includes a method for validating user input, and an interface for the authentication module that includes a method for logging in a user.
- Extension: The third step is to create new modules that implement the defined interfaces to add new functionality to the login form component. For example, we can create a new validation module that implements the validation interface and provides more robust input validation rules. Similarly, we can create a new authentication module that implements the authentication interface and provides support for different authentication methods.
- Open for Extension: The final step is to ensure that the login form component is open for extension by allowing it to accept any module that implements the defined interfaces. This means that the component should not have any hard-coded dependencies on specific modules but should be designed to accept any module that meets its requirements. For example, we can modify the login form component to accept any validation or authentication module that implements the respective interface.
To apply the Open/Closed Principle to our login form component, we can separate the concerns of user input validation and login authentication into two separate modules. This way, if we need to change the validation rules or the authentication method in the future, we can do so without modifying the original code of the login form component.
Let’s take a look at how we can achieve this in our example code.
First, we can create a separate module for user input validation. This module will be responsible for validating the user’s input according to a set of rules. Here’s an example implementation:

This module takes in the username and password input as arguments and checks if they meet the validation rules. If the input is invalid, it throws an error with a descriptive message.
Next, we can create another module for login authentication. This module will be responsible for checking if the user’s input is valid and authenticating the user. Here’s an example implementation:
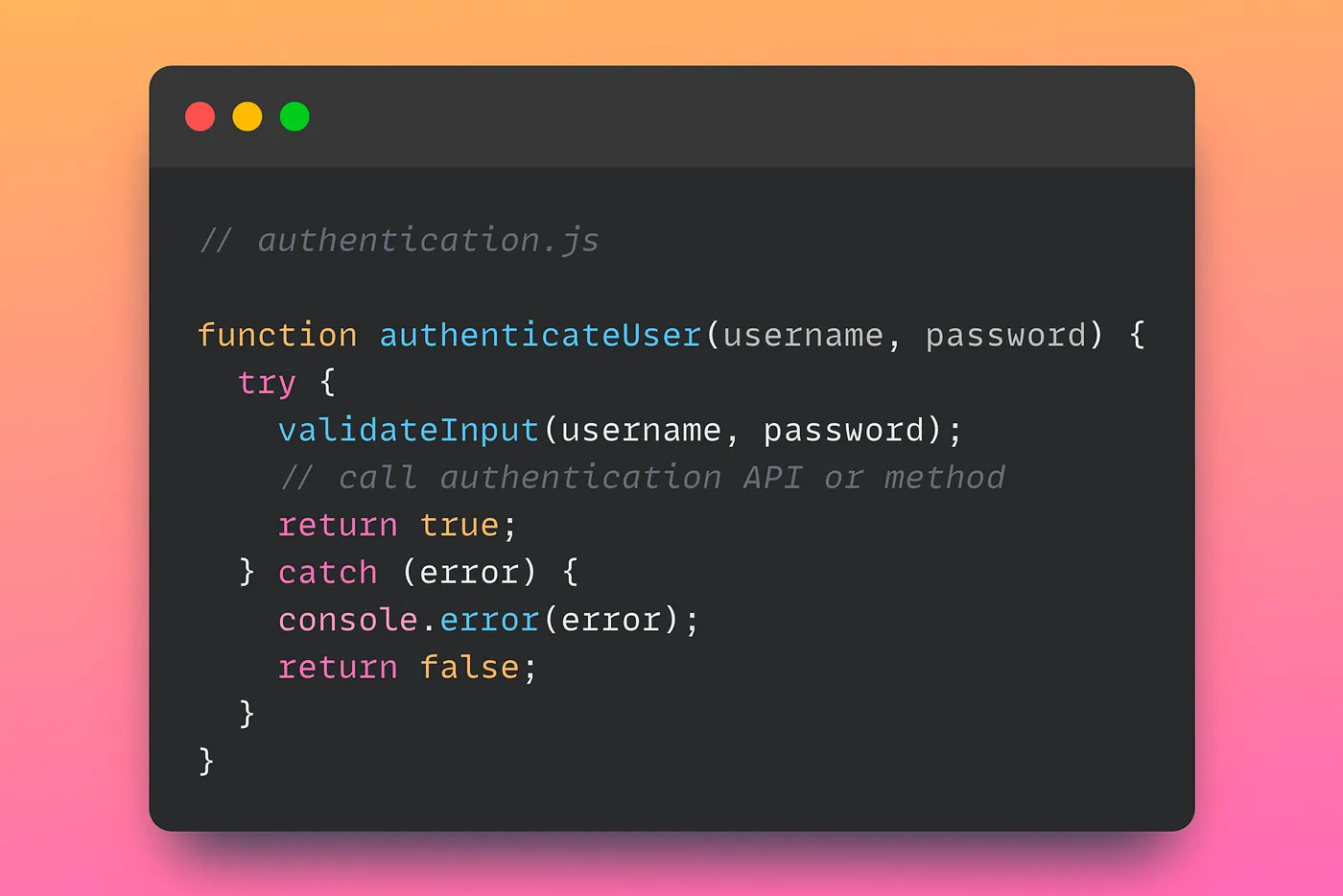
This module first calls the validateInput function to check if the input is valid. If the input is valid, it then calls an authentication API or method to authenticate the user. If the authentication is successful, it returns true. If the authentication fails or the input is invalid, it logs an error message and returns false.
Finally, we can modify our original login form component to use the authenticateUser function from the authentication module to handle user authentication. Here's how the modified component would look like:
import { useState } from 'react';
import { authenticateUser } from './authentication';
function LoginForm() {
const [username, setUsername] = useState('');
const [password, setPassword] = useState('');
const [isLoggedIn, setIsLoggedIn] = useState(false);
function handleSubmit(event) {
event.preventDefault();
if (authenticateUser(username, password)) {
setIsLoggedIn(true);
}
}
if (isLoggedIn) {
return <p>You are logged in!</p>;
}
return (
<form onSubmit={handleSubmit}>
<label>
Username:
<input type="text" value={username} onChange={(e) => setUsername(e.target.value)} />
</label>
<br />
<label>
Password:
<input type="password" value={password} onChange={(e) => setPassword(e.target.value)} />
</label>
<br />
<button type="submit">Log in</button>
</form>
);
}Notice that the handleSubmit function now calls the authenticateUser function instead of handling validation and authentication logic directly. This way, we have separated the concerns of input validation and authentication into two separate modules, which makes the code easier to maintain and extend in the future.
In summary, the Open/Closed Principle states that software entities (classes, modules, functions, etc.) should be open for extension but closed for modification. To apply this principle, we separated the concerns of user input validation and login authentication into two separate modules and modified the original login form component
3. Liskov Substitution Principle (LSP):
The Liskov Substitution Principle (LSP) is a fundamental principle of object-oriented programming that states that objects of a superclass should be able to be replaced with objects of its subclass without affecting the correctness of the program. In simpler terms, if a program is designed to work with an object of a certain class, it should work with objects of any subclasses of that class without any issues.
In the case of the simple login form component, the LSP could be violated if a subclass of the LoginForm component were to behave differently than the superclass. For example, if a subclass were to override the handleInputChange method to do something completely different than what the superclass does, it could cause unexpected behavior in the application.
To avoid violating the LSP, any subclasses of LoginForm should only extend its functionality without changing or removing any of the behaviors defined in the superclass. They should only add new functionality that is not already present in the superclass.
To illustrate this, let’s consider a functional implementation of LoginForm and LoginFormWithGoogle. LoginForm is defined as a function that takes in a username and password as parameters and defines the validateInput and authenticate methods. LoginFormWithGoogle is defined as a function that takes in a username, password, and googleToken as parameters and first calls the LoginForm function to get the validateInput and authenticate methods. It then defines a new authenticateWithGoogle method that adds Google OAuth authentication logic on top of the authenticate method from the parent class. Finally, it returns an object with the authenticateAndGoogle method that calls validateInput, authenticate, and authenticateWithGoogle.
In this way, we can ensure that the program will continue to work correctly even if different subclasses of LoginForm are used interchangeably with the superclass. This is the essence of the Liskov Substitution Principle.
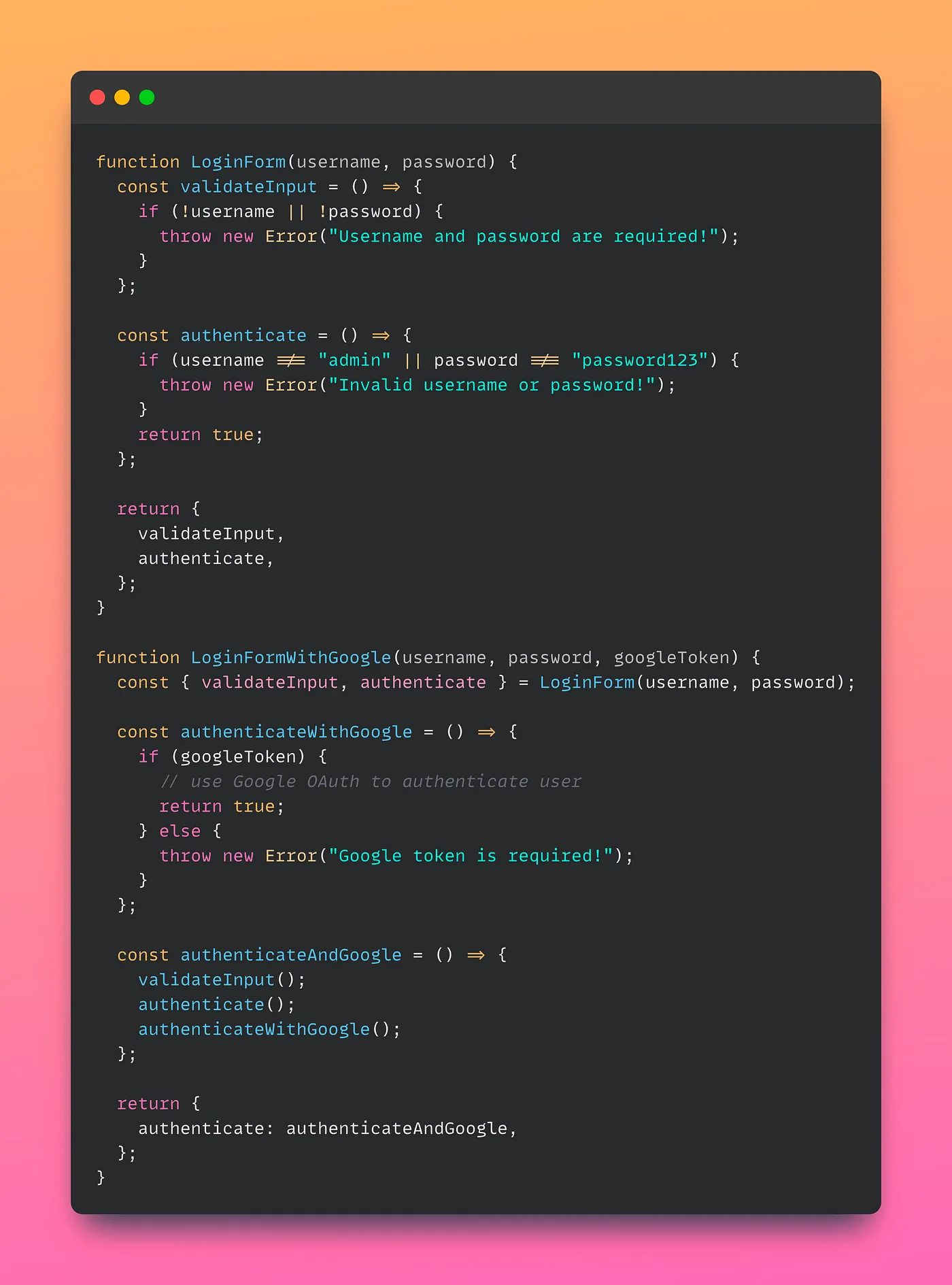
In this functional version, LoginForm and LoginFormWithGoogle are defined as functions that return objects containing validateInput and authenticate methods. The LoginForm function takes in username and password as parameters and defines the validateInput and authenticate methods. The LoginFormWithGoogle function takes in username, password, and googleToken as parameters and first calls the LoginForm function to get the validateInput and authenticate methods. It then defines a new authenticateWithGoogle method that adds the Google OAuth authentication logic on top of the authenticate method from the parent class. Finally, it returns an object with the authenticateAndGoogle method that calls validateInput, authenticate, and authenticateWithGoogle.
This functional version follows the Liskov Substitution Principle because the authenticateAndGoogle method in LoginFormWithGoogle calls both validateInput and authenticate methods from the parent class, and then adds the Google OAuth authentication logic on top of that. This ensures that the behavior of the parent class is not changed in a way that is unexpected.
4. Interface Segregation Principle (ISP):
It is fundamental principles of software design that aims to promote code modularity, flexibility, and maintainability. It states that clients should not be forced to depend on interfaces they don’t use. In other words, when designing a class or component, it’s better to create smaller, more focused interfaces that serve specific client needs rather than large, monolithic interfaces that force clients to implement methods they don’t need or use.
In the context of the above example code on the simple login form component, the ISP suggests that we should design the component in a way that only exposes the necessary methods that clients need, and not any more. This means that we should avoid having a single large interface that contains both input validation and login authentication methods.
One way to achieve this is by separating the input validation and login authentication functionalities into their own interfaces. For example, we could define a “Validation” interface that only contains the “validateInput” method, and a “Authentication” interface that only contains the “authenticate” method. Then, we could have the LoginForm component implement both interfaces, and any subclass that needs to extend either functionality could implement the corresponding interface.
Here is an example implementation of the LoginForm component that follows the ISP:
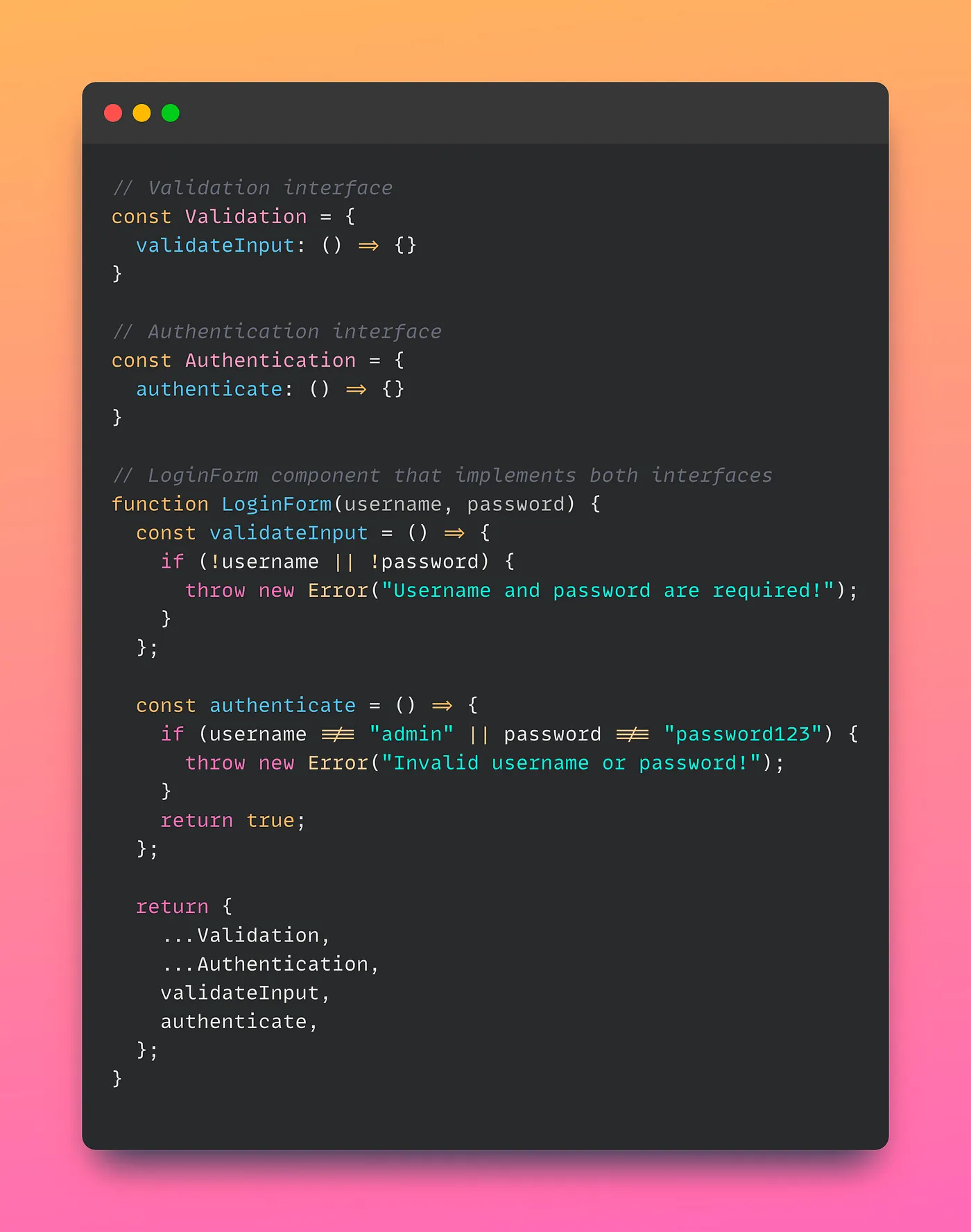
With this implementation, any client that only needs to perform input validation can depend on the Validation interface, while any client that only needs to perform login authentication can depend on the Authentication interface. Clients that need to perform both input validation and login authentication can depend on both interfaces.
This implementation adheres to the ISP because it provides smaller, more focused interfaces that are more flexible and maintainable. Clients are not forced to depend on methods they don’t need or use, and the component can be easily extended without affecting the clients that only use specific functionalities.
5. Dependency Inversion Principle (DIP):
It is fundamental principles of software design that aims to promote flexibility, reusability, and maintainability by reducing coupling between modules. The principle states that high-level modules should not depend on low-level modules, but both should depend on abstractions.
In the context of the above example code on the simple login form component, the LoginForm component is a low-level module that handles both user input validation and login authentication. According to DIP, this component should not depend on any specific implementation of its dependencies, but instead depend on abstractions.
To apply DIP to the LoginForm component, we can define two abstract interfaces that represent its dependencies: “InputValidation” and “UserAuthentication”. These interfaces define the methods that the LoginForm component needs to perform its tasks, without specifying any specific implementation.
Here is an example implementation of the LoginForm component that follows DIP:
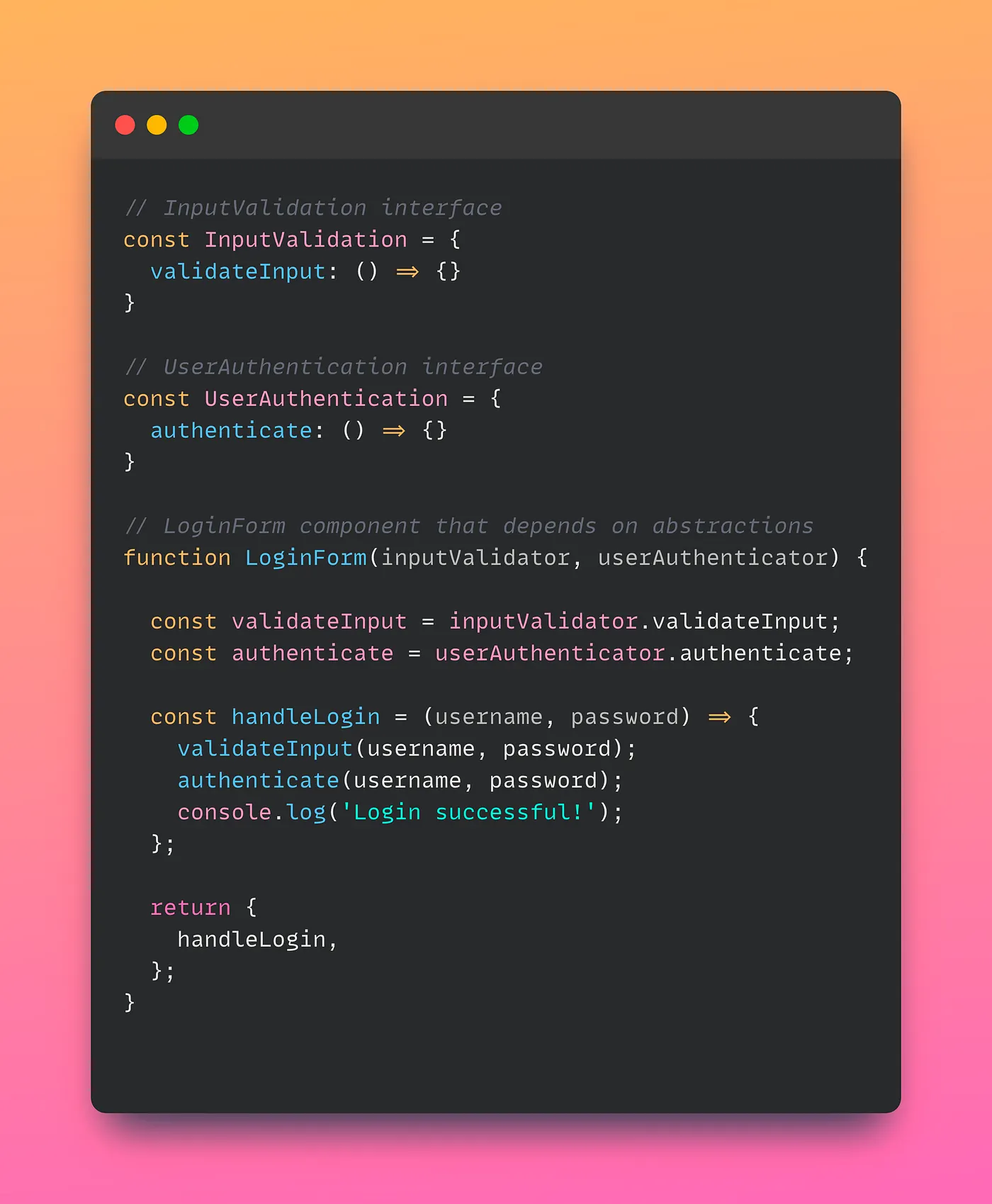
In this implementation, the LoginForm component takes in two dependencies as arguments: an “inputValidator” that implements the InputValidation interface, and a “userAuthenticator” that implements the UserAuthentication interface. These dependencies are injected into the component at runtime, rather than being hard-coded or tightly coupled.
The LoginForm component then uses these dependencies to perform its tasks in the “handleLogin” method. The method first calls the “validateInput” method of the “inputValidator” to validate the user input, and then calls the “authenticate” method of the “userAuthenticator” to authenticate the user. Finally, it logs a message to the console to indicate that the login was successful.
This implementation adheres to the Dependency Inversion Principle because the LoginForm component depends on abstractions rather than concrete implementations. This makes the component more flexible and maintainable, as it can be easily extended or replaced with different implementations of the InputValidation and UserAuthentication interfaces, without affecting the component’s behavior. Additionally, this implementation promotes reusability and modularity by decoupling the LoginForm component from its dependencies.
Beneficts of using SOLID principles in software development:
- Maintainability: By creating classes that have a single responsibility, and that are open for extension but closed for modification, it becomes easier to maintain and modify the code. Changes can be made to a specific area of the code without affecting the rest of the system.
- Testability: Classes that have a single responsibility and that are modular are easier to test. This is because the behavior of each class can be tested in isolation, without relying on other parts of the system.
- Scalability: SOLID principles promote modularity, which makes it easier to scale a system. New functionality can be added without having to modify existing code, reducing the risk of introducing bugs or causing unintended side-effects.
- Flexibility: By using abstractions and defining dependencies between modules, SOLID principles make code more flexible. This means that changes can be made to the system without affecting other parts of the code.
- Reusability: By creating modular, reusable code, developers can reduce the amount of duplicate code in a system, which can save time and reduce the risk of introducing bugs.
Overall, the SOLID principles help developers to create code that is easier to understand, maintain, and scale, and that is more resilient to change. This can lead to more efficient and effective software development, with fewer bugs and faster delivery times.
